Lokale, private KI-Wissensdatenbank. Läuft komplett offline auf deinem Rechner. Dokumente und Web-Seiten werden in Vektoren überführt und können per Chat (lokales LLM oder optional OpenAI / Gemini / Claude) abgefragt werden.
KnowSora ist ein selbst-gehosteter KI-Assistent mit RAG-Wissensdatenbanken, neun austauschbaren LLM-Providern (inkl. xAI Grok und OpenRouter), einem Skill-System mit eingebauten Tools (KI-Bild- und Video-Generierung, Projekt-Datei- Zugriff für jede KI, Shell-Ausführung), Projekt-Verzeichnissen mit universellem File-Preview und einem Web-Terminal für SSH-Zugriff.
Dokumentation Stand Mai 2026 — wenn etwas in der App anders aussieht, gilt die App. Aktuelle Version enthält:
manage.sh (UGREEN-tauglich).env.example-----
# 1. Code holen oder ZIP entpacken
cd /volume3/docker/knowsora
unzip -o knowsora_release.zip # falls als ZIP geliefert
# 2. Starten — manage.sh erledigt .env + SECRET_KEY + Docker
./manage.sh start
# 3. Im Browser
http://<NAS-IP>:47822
Beim ersten Start wird admin / admin angelegt — direkt nach dem Login in den Admin-Bereich, eigenes Passwort setzen.
Was ./manage.sh start automatisch macht:
.env aus .env.example anlegen (falls noch nicht da).env.example werden in deinebestehende .env nachgepflegt (alte Werte bleiben erhalten)
SECRET_KEY generieren falls leer (via openssl / python3 / /dev/urandom)und persistent in /data/.secret_key ablegen
./manage.sh logs-----
wird; ohne lokales LLM reichen 4 GB)
/dev/dri für VAAPI-Beschleunigung beimlokalen LLM (Intel N100, Pentium Gold 8505, N-Series)
Neue Release-ZIP bekommen → einfach ins Projektverzeichnis legen und updaten:
cd /volume3/docker/knowsora
# knowsora_release.zip dort ablegen (z.B. per scp/SFTP/Web-Upload)
./manage.sh update
manage.sh update macht automatisch:
manage.sh selbst(versucht unzip → python3 → python → docker run alpine, je nach dem was auf dem Host verfügbar ist — funktioniert auch auf UGREEN/Synology ohne unzip-Paket)
.env.example nach .env(bestehende Werte werden NIE überschrieben, nur neue Keys ergänzt)
unprivileged_usernsblockiert (NAS-typisch)
Bei Build-Cache-Problemen oder kaputten Images:
docker compose down
docker rmi knowsora-backend:latest knowsora-frontend:latest
./manage.sh update
Build-Logs werden mit --progress plain ausgegeben — keine animierten Spinner mehr, jeder Step erscheint einmal als reine Textzeile (wichtig für SSH-Sessions ohne voll-interaktives TTY).
-----
./manage.sh start legt die .env automatisch aus .env.example an und generiert den SECRET_KEY. Manuell bearbeiten nur wenn du Defaults ändern willst (Ports, Daten-Pfad, Timeouts, Provider-Keys vorab).
Standard-Felder die du eventuell anpassen willst:
|Variable |Bedeutung |Beispiel / Default | |-----------------|--------------------------------------------------|------------------------------------| |SECRET_KEY |JWT-Signatur + Ableitung des Verschlüsselungs-Keys|Wird automatisch generiert wenn leer| |FRONTEND_PORT |Port der Web-UI |47822 | |BACKEND_PORT |Port der API |48823 | |LLAMA_CHAT_PORT|Port des lokalen LLM |48824 | |ADMIN_PASSWORD |Initial-PW für Admin-User |admin (sofort ändern!) |
Optional aber empfohlen:
|Variable |Default |Zweck | |-----------------------|----------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------| |HOST_UID / HOST_GID|1000:1000 |UID/GID unter der die Container laufen — passt File-Permissions auf dein NAS-Volume an | |DATA_DIR |/data |Im-Container-Pfad für persistente Daten | |MEDIA_ROOT |/data/media |KI-generierte Bilder/Videos | |UPLOAD_DIR |/data/uploads |Chat-Attachments + Provider-Output-Files | |LLM_HTTP_TIMEOUT |3600 |Sekunden — für lange KI-Antworten | |CLAUDE_CLI_TIMEOUT |3600 |Claude Code CLI Hardcap pro Call | |CODEX_CLI_TIMEOUT |3600 |Codex CLI Hardcap pro Call | |GEMINI_CLI_TIMEOUT |3600 |Gemini CLI Hardcap pro Call | |VEO_MODEL |veo-3.0-generate-001|Video-Gen-Modell — veo-2.0-generate-001 falls Veo 3 nicht freigeschaltet | |VEO_MAX_POLL_S |600 |Maximale Wartezeit für Video-Rendering | |PROJECT_SHELL_TIMEOUT|90 |Sekunden — Hardcap für project_run_shell-Tool | |CODEX_SANDBOX_MODE |(leer) |NAS-Workaround: danger-full-access wenn kernel.unprivileged_userns_clone=0 (UGREEN/Synology). Werte: read-only, workspace-write, danger-full-access|
Wichtig zur Verschlüsselung:SECRET_KEYniemals ändern wenn schon Daten in der DB sind. Sonst sind alle verschlüsselten API-Keys unbrauchbar und alle Sessions müssen neu eingeloggt werden. Beim ersten Start wird der Key automatisch in/data/.secret_keypersistiert — beide Pfade (.envund.secret_key) sollten Teil deines Backups sein. Der Fernet-Verschlüsselungs-Key für API-Keys in der DB wird per PBKDF2 ausSECRET_KEYabgeleitet — eine separateFERNET_KEY-Variable gibt es nicht.
-----
manage.sh ist mehr als nur docker compose-Wrapper. Bei jedem start oder update laufen automatisch:
Wird eine knowsora_release.zip im Projekt-Root abgelegt die neuer ist als die letzte ausgepackte Version, entpackt manage.sh sie selbst. Fallback-Kette für Hosts ohne unzip-Paket:
1. unzip Standard auf Linux mit zip-Tools
2. python3 -m zipfile überall wo Python 3 vorhanden ist (z.B. UGREEN)
3. python -m zipfile Python 2 Fallback
4. docker run alpine letzter Notnagel — Docker ist sowieso da
Nach erfolgreicher Extraktion wird der ZIP-mtime 24h in die Vergangenheit gesetzt, damit der Auto-Trigger nicht endlos feuert. Beim nächsten Re-Upload einer ZIP (neuer mtime) greift er wieder.
Log-Ausgabe:
[KnowSora] Neue knowsora_release.zip erkannt — entpacke automatisch...
[KnowSora] → 'unzip' fehlt, verwende python3 zipfile
[OK] knowsora_release.zip entpackt
.env.examplePflegt fehlende ENV-Variablen aus .env.example in deine .env nach ohne bestehende Werte zu überschreiben. Nur Keys die in .env komplett fehlen werden angehängt — auskommentierte Werte (# FOO=...) gelten als “bewusst deaktiviert” und werden nicht aktiviert.
Nachgepflegte Keys landen am Ende der .env unter:
# ─── Automatisch nachgepflegt aus .env.example ───
Damit bekommst du bei Updates automatisch alle neuen Konfig-Optionen ohne deine eigenen Werte zu verlieren.
Erkennt automatisch wenn der Host-Kernel unprivileged_userns_clone=0 hat (typisch für UGREEN, Synology, manche Docker-Setups) und setzt CODEX_SANDBOX_MODE=danger-full-access in der .env.
Hintergrund: Codex CLI nutzt bubblewrap als Sandbox. Auf Kerneln ohne unprivileged user namespaces scheitert bwrap mit “No permissions to create a new namespace” und Codex bricht ab. Der Container ist sowieso durch Docker isoliert, also kein realer Sicherheitsverlust.
Logik: nur wenn CODEX_SANDBOX_MODE= leer in .env UND sysctl kernel.unprivileged_userns_clone == 0. Hast du den Wert manuell gesetzt (egal ob danger-full-access, read-only oder etwas anderes), wird er nicht angetastet.
-----
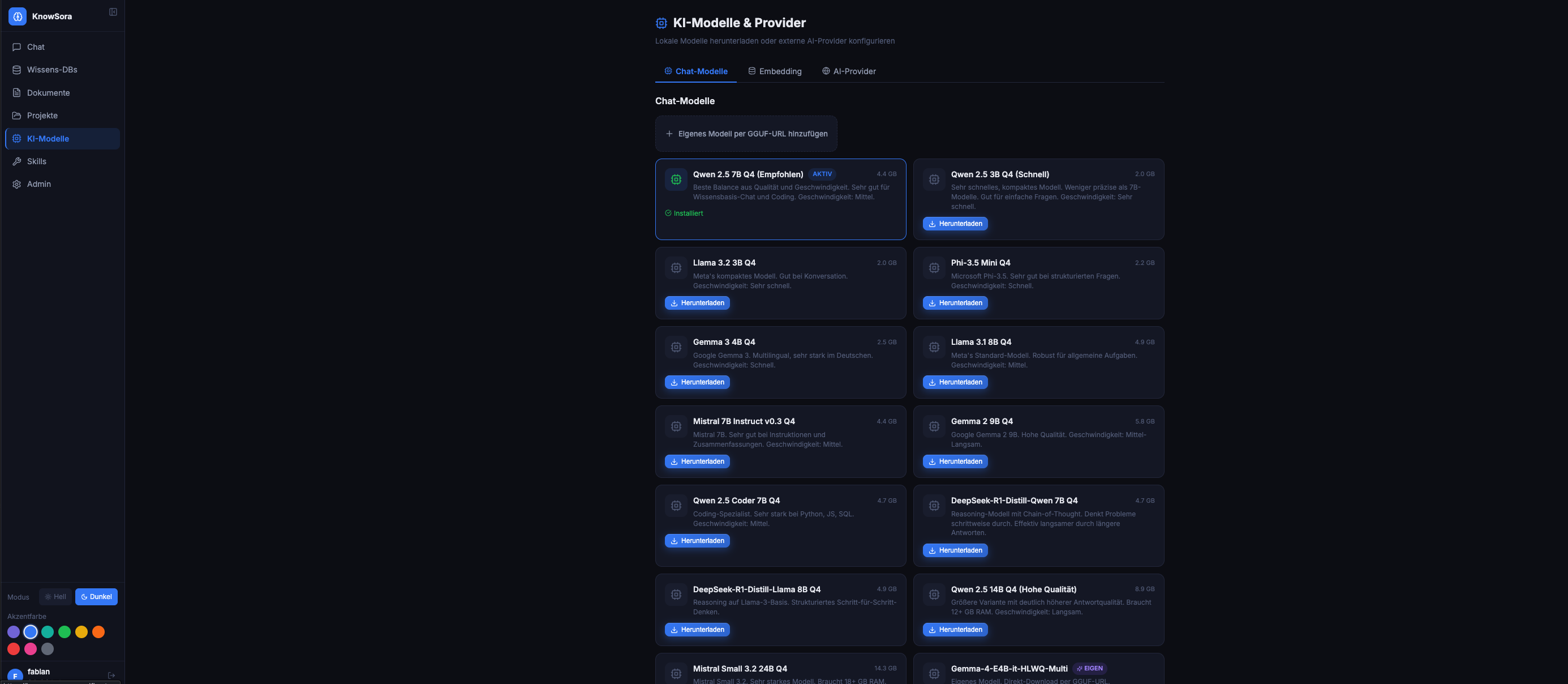
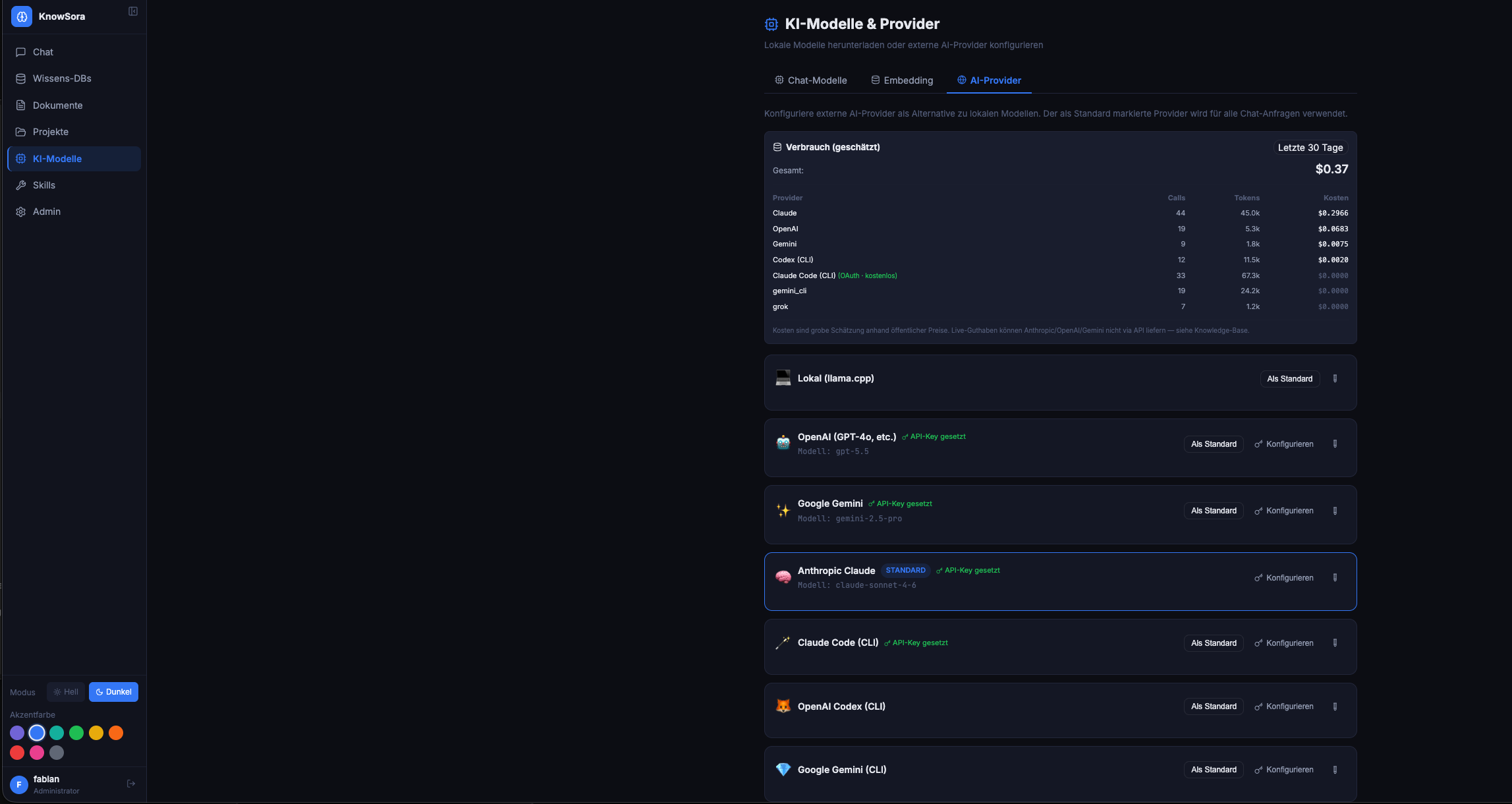
KnowSora unterstützt neun Provider — alle parallel nutzbar. Auswahl pro Chat via Provider-Pille oben links.
Läuft im Container knowsora-llama-chat. Modell-Auswahl: GGUF-Datei in /data/models/ ablegen, in .env setzen:
CHAT_MODEL_PATH=/models/qwen3-4b-q4_k_m.gguf
Container neu starten. Empfehlung für 4-GB-Mode: Qwen3-4B-Q4_K_M. Für 8 GB: Qwen3-7B-Instruct-Q4_K_M.
KI-Modelle → OpenAI → API-Key + Modell-ID (z.B. gpt-4o, gpt-5, o1-mini).
KnowSora erkennt automatisch ob das Modell max_completion_tokens statt max_tokens braucht (gpt-5, o1, o3, o4) und ob temperature unterstützt wird. Bei API-Fehlern wird zweimal retried mit passenden Feldern bevor aufgegeben wird.
KI-Modelle → Claude → API-Key + Modell-ID (z.B. claude-sonnet-4-5, claude-opus-4-7).
KI-Modelle → Gemini → API-Key + Modell-ID (gemini-2.5-pro, gemini-2.5-flash, gemini-3-pro-preview).
Hinweis: Preview-Modelle sind oft nur für bestimmte Accounts/Regionen freigeschaltet. Bei 503 oder “not found” auf ein Stable-Modell wechseln.
KI-Modelle → xAI Grok → API-Key (auf console.x.ai generieren). Modell-Vorschläge:
grok-4.3 (Default) — schnell + günstig, gute Tool-Callsgrok-4.20 — Flagship-Reasoninggrok-imagine-image-quality — Bildgenerierung (vom Medien-Generatorvia provider="grok" aufrufbar)
grok-imagine-video — Videogenerierung (via Medien-Generator)Auth: xAI hat kein OAuth-Verfahren für die API. Auch nicht mit X Premium / SuperGrok-Abo. Ausschließlich API-Key. Credits müssen explizit aufgeladen werden, Free-Tier gibt es nicht.
KI-Modelle → OpenRouter → API-Key (auf openrouter.ai generieren, Google-/GitHub-Login möglich, kein Karten-Hinterlegen für Free-Tier nötig).
Was OpenRouter besonders macht: Ein API-Key, Zugang zu 300+ Modellen von OpenAI, Anthropic, Google, xAI, Meta, DeepSeek, Mistral u.v.m. — inkl. dedizierter Free-Tier-Modelle für komplett kostenlose Nutzung (mit Rate-Limit).
Empfohlene Modell-Wahl:
openrouter/free (Default, Killer-Feature) — Smart-Routing, wähltzur Laufzeit das beste Free-Modell passend zum aktiven Skill: - Coding-Assistent → Qwen3 Coder (1M Context) - Wissens-Recherche → Llama 3.3 70B / DeepSeek V4 / Gemini 2.0 Flash - Daten-Analyst → DeepSeek V4 Flash (Reasoning) - Web-Recherche → Llama 3.3 / DeepSeek - Medien-Generator → erstes Allzweck-Free-Modell mit Tool-Support - Coder-Modelle werden bei Nicht-Coding-Skills automatisch ausgeschlossen (anti_hints in der Heuristik)
qwen/qwen3-coder:free — Top-Coding-Modell, 1M Contextdeepseek/deepseek-v4-flash:free — Reasoning, 1M Contextmeta-llama/llama-3.3-70b-instruct:free — Solider Allzweckgoogle/gemini-2.0-flash-exp:free — Multimodal, schnellopenai/gpt-5 — kostenpflichtig, falls Credits aufgeladenanthropic/claude-sonnet-4.6 — kostenpflichtigPer-Skill-Override: Du kannst pro Skill ein bevorzugtes Free-Modell in Skills → Bearbeiten → “🌐 Bevorzugtes OpenRouter Free-Modell” pinnen. Smart-Routing nutzt dann dieses statt der Heuristik. Leer lassen für Auto-Wahl.
Rate-Limits (Stand Mai 2026):
20 req/min
KnowSora-Features für OpenRouter:
openrouter/smart) — wählt zur Laufzeit das besteFree-Modell passend zum aktiven Skill (Capability-Scoring nach Tool-Support, Context-Größe, Modell-Familie)
/api/v1/models geladen (1h Cache)
gekaufte und verbrauchte Credits
erreicht hat, probiert KnowSora automatisch bis zu 2 weitere Free-Modelle (filtert auf Tool-Calling-fähige falls Skill aktiv)
HTTP-Referer +X-Title-Header damit deine Nutzung auf den OpenRouter-Leaderboards erscheint
Cache-Refresh falls neue Free-Modelle erwartet werden:
curl -X POST http://localhost:48823/api/openrouter/refresh-cache \
-H "Authorization: Bearer $YOUR_KNOWSORA_TOKEN"
Für andere Hoster mit OpenAI-API-Format (Together, Groq, lokale APIs, etc.). KI-Modelle → Custom → Base-URL + API-Key + Modell-ID.
OpenRouter sollte über den dedizierten Provider (Nr. 6) genutzt werden — sonst entgehen dir Free-Tier-Detection, Auto-Fallback und Credits- Anzeige.
Drei lokal in den Backend-Container installierte CLIs. Login per OAuth (kostenlos für Pro/Plus/Subscription-User) oder API-Key.
Subscription-Übersicht (ohne extra API-Kosten):
|CLI |Subscription |Kostenmodell | |-----------|---------------------|---------------------------------------------| |Claude Code|Anthropic Pro/Team |5 Std-Limits, max ~50 Anfragen/5h | |Codex |ChatGPT Plus/Pro/Team|Im ChatGPT-Plan inklusive | |Gemini CLI |Google-Account (Free)|1000 Anfragen/Tag mit Gemini 2.5 Flash gratis|
OAuth-Login-Workflow (alle drei gleich):
einloggen, Code zurück ins Terminal
Nach erfolgreichem Login: KnowSora erkennt OAuth-Token automatisch periodisch (alle 2 Sek) und schließt das Login-Fenster.
Wichtig — CLI im Container-Mode: Der Backend-Container fügt beim Start automatisch einen passwd-Eintrag für die Container-UID ein. Sonst crashen Node-basierte CLIs (insbesondere Gemini’s FileKeychain) mit uv_os_get_passwd returned ENOENT. Falls Probleme: Backend neu starten, dann läuft ensure_passwd_entry() erneut.
-----
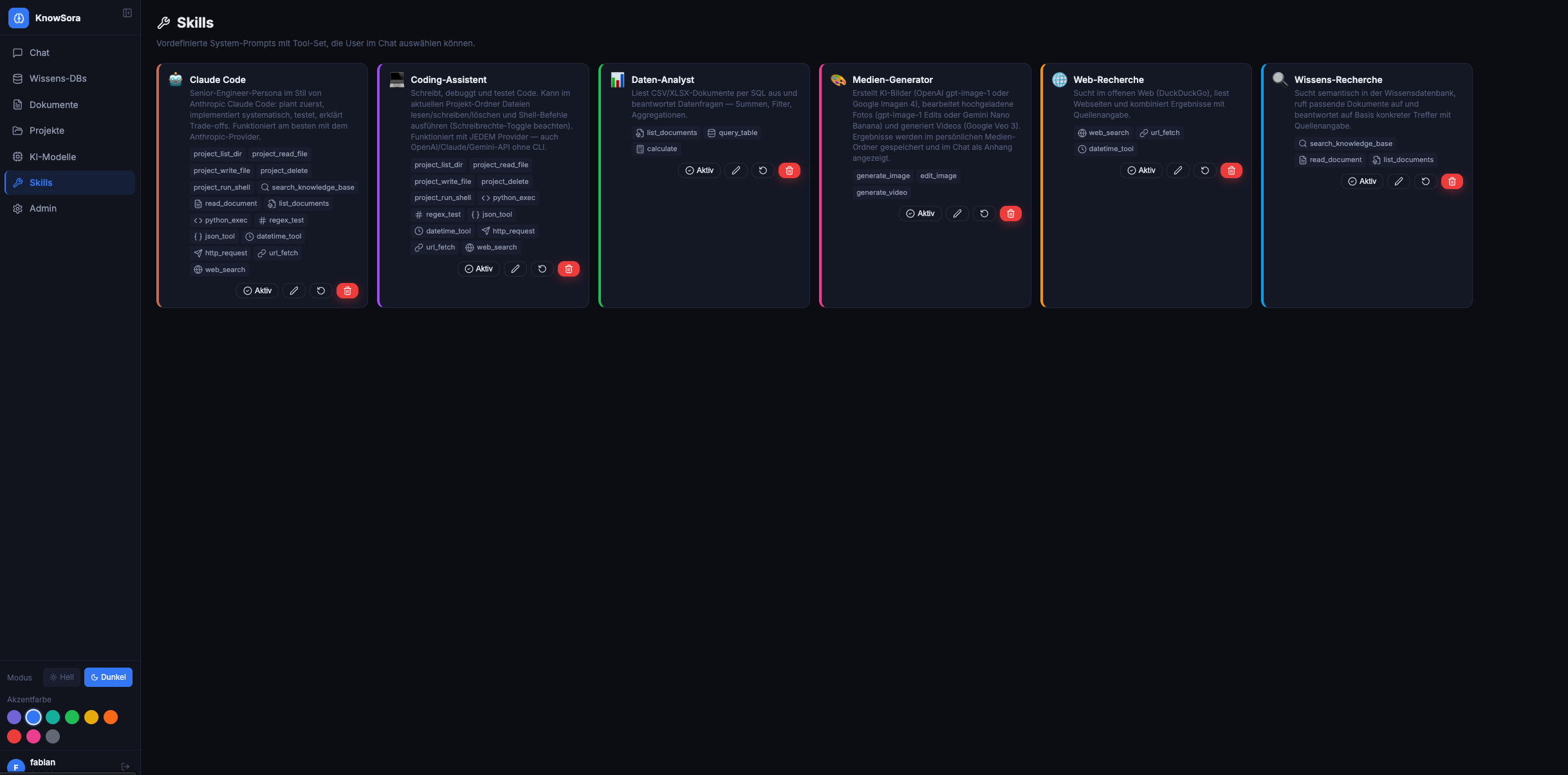
Ein Skill = System-Prompt + Tool-Whitelist. Beim Chat-Start in der Skill- Pille auswählbar. Wenn ein Skill aktiv ist, läuft die KI in einer Tool- Loop und kann die freigeschalteten Tools aufrufen.
Mitgelieferte Default-Skills:
|Skill |Tools |Zweck | |-----------------------|-------------------------------------------------------------------------------------------------|-------------------------------------------------| |🪄 Wissens-Recherche|search_knowledge_base, read_document, list_documents |RAG-Antworten mit Quellenangabe | |🌐 Web-Recherche |web_search, url_fetch, datetime_tool |DuckDuckGo + Webseiten lesen | |📊 Daten-Analyst |list_documents, query_table, calculate |CSV/XLSX per SQL auswerten | |💻 Coding-Assistent |project_, python_exec, regex_test, json_tool, datetime_tool, http_request, url_fetch, web_search|Code schreiben/testen, im Projekt-Ordner arbeiten| |🤖 Claude Code |project_, alle Coding-Tools + KB-Suche |Senior-Engineer-Persona mit Projekt-Tools | |🎨 Medien-Generator |generate_image, edit_image, generate_video |Bilder/Videos via OpenAI + Google + Grok |
Skills sind editierbar (Admin → Skills) — System-Prompt + Tool-Liste + Icon + Farbe pro Skill. “Standard zurücksetzen” pro Skill verfügbar. Neue Skills aus Updates werden inkrementell nachgepflegt, deine Anpassungen bleiben erhalten.
search_knowledge_base — Hybrid-Suche (BM25 + Vektor mit Reciprocal Rank Fusion) in einer KB. Liefert Top-10-Chunks mit Quellen-Metadaten (Max 20). Findet auch Eigennamen und exakte Begriffe zuverlässig, nicht nur semantisch ähnliche Inhalte.
read_document / list_documents — Volltext eines Dokuments laden / Dateien einer KB auflisten.
query_table — DuckDB-SQL über CSV/XLSX-Dokumente einer KB. Ideal für “Wie viele Bestellungen letzten Monat?” oder Aggregationen.
calculate — Python-Math-Ausdrücke (sandboxed).
python_exec — Voll-Python-Sandbox in eigenem Subprocess, mit Output-File-Capture. Dateien die unter /tmp/ erzeugt werden, landen automatisch als Download-Button im Chat.
web_search / url_fetch — DuckDuckGo-Suche + Webseiten als Markdown lesen (BS4 + Readability).
http_request — Beliebige HTTP-Calls (GET/POST/PUT/DELETE) mit Headers + Body. Whitelist gegen interne IPs.
json_tool / regex_test / datetime_tool — Hilfsfunktionen zum Parsen, Pattern-Matchen, Zeit-Berechnungen.
Diese Tools erlauben es jeder KI (auch OpenAI/Claude/Gemini-API, nicht nur CLIs), direkt im aktuellen Projekt-Verzeichnis zu arbeiten:
project_list_dir — Verzeichnis-Inhalt anzeigen (max 500 Einträge, optional rekursiv).
project_read_file — Datei lesen bis 1 MB (optional max_lines). Keine Schreibrechte nötig.
project_write_file — Datei schreiben oder anhängen, max 5 MB. Verzeichnisse werden auto-erstellt. Braucht aktivierte Schreibrechte im Projekt.
project_delete — Datei oder Verzeichnis löschen (rekursiv bei Ordnern). Braucht aktivierte Schreibrechte.
project_run_shell — Shell-Befehl im Projekt-cwd ausführen (npm install, python -m pytest, git status, etc.). Hartes Timeout 90 Sek (PROJECT_SHELL_TIMEOUT änderbar), stdout/stderr auf 50 KB gekappt. Braucht aktivierte Schreibrechte.
Schreibrechte-Toggle pro Projekt — gleiche Logik wie für die CLIs:
fehl, list/read funktionieren weiterhin
Cross-Provider-Workflow: Damit kann GPT-5 prüfen was Claude Code gerade im Projekt gebaut hat, oder Gemini ein von Claude erzeugtes Python-Script auf Bugs durchsehen.
generate_image — KI-Bildgenerierung. Parameter provider:
openai (Default) — gpt-image-1, fotorealistisch, ggf. Org-Verificationgemini — imagen-4.0-generate-001, künstlerisch starkgrok — grok-imagine-image-quality, fotorealistisch + starke Text-Wiedergabeedit_image — Bild-zu-Bild auf Basis eines hochgeladenen Fotos. Nutzt automatisch das erste Image-Attachment der aktuellen Nachricht (attachment_index=0). JPEGs werden serverseitig zu PNG konvertiert (Pillow), bevor sie an OpenAI’s /images/edits-Endpoint gehen.
openai — gpt-image-1 Edits, fotorealistischgemini — gemini-2.5-flash-image (Nano Banana), kreativgrok — grok-imagine-image-quality Edits, Base64-data-URI als Inputgenerate_video — Video-Generierung. Parameter provider:
gemini (Default) — Google Veo 3, 4-8 Sek, ca. 1-3 min Wartezeitgrok — grok-imagine-video, 5-15 Sek, ~30 Sek WartezeitOpenAI und Anthropic haben keine öffentliche Video-API. Sora ist nur in ChatGPT verfügbar, nicht via API.
Drei Speicherorte parallel:
/data/media/<user_id>/<YYYY-MM-DD>/<uuid>.png # Original-Ablage
/data/uploads/... # Provider-Output-Files
<projekt>/outputs/<YYYY-MM-DD>/<original_name> # Wenn Chat ein Projekt hat
Jedes generierte File wird als ChatOutput-DB-Row persistiert — bleibt nach Tab-Wechsel und Browser-Neustart in der Chat-Historie sichtbar mit Inline-Preview (Bilder: <img>, Videos: <video controls>).
Wenn der Chat ein Projekt zugewiesen hat:
Alle Outputs werden zusätzlich automatisch als Kopie ins Projekt- Verzeichnis abgelegt (<projekt>/outputs/<datum>/). Bei Namens- konflikten wird ein Counter angehängt (bild.png → bild (1).png).
Die Projekt-Kopie ist komplett unabhängig von der DB: Chat löschen, ChatOutput löschen, Original in /data/media/ löschen — alles beeinflusst die Projekt-Kopie nicht. Nur das Löschen des Projekts selbst (oder manuell per Datei-Browser) entfernt sie.
Nachträglich kopieren: Im Chat-Header gibts einen Button „→ Projekt” (erscheint nur wenn Projekt zugewiesen). Damit werden alle bisherigen Outputs des Chats in einem Rutsch ins Projekt kopiert — nützlich für Outputs die VOR der Projekt-Zuweisung entstanden sind.
-----
automatisch (sofern der Skill search_knowledge_base enthält)
Unterstützte Formate: PDF, DOCX, XLSX, CSV, TXT, MD, HTML, JSON, PPTX.
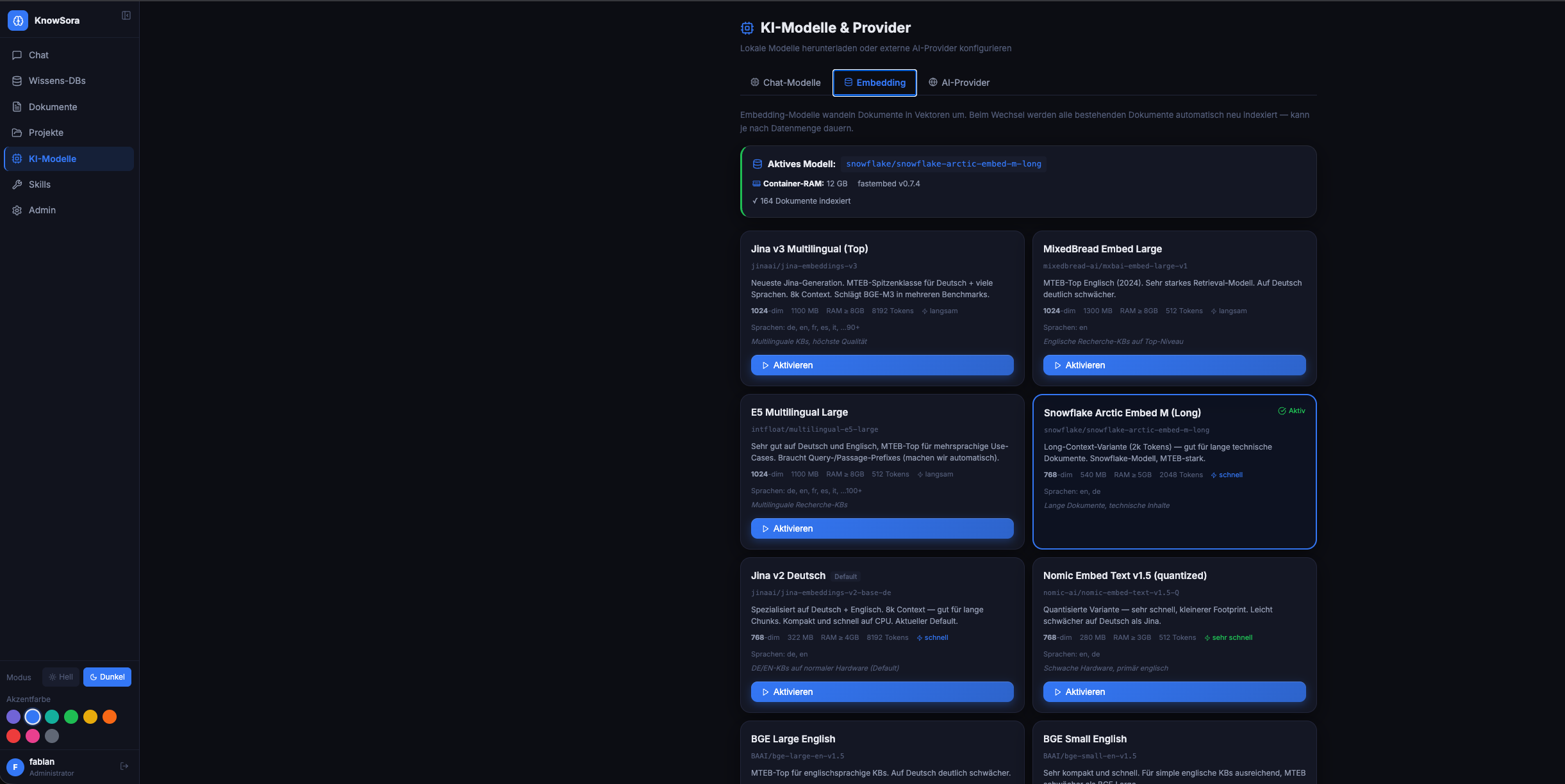
Indexierung: läuft als Background-Worker. Status im Dokumenten- Listing (pending → processing → ready).
Embedding-Modell: Default nomic-embed-text-v1.5 (768-dim, ONNX, in-process via fastembed — kein separater Container). Im Admin-Bereich unter “Embed-Modelle” wechselbar (löst Auto-Reembed aller Dokumente aus).
-----
Projekte sind persistente Arbeitsverzeichnisse pro User unter /data/projects/<user_id>/<slug>/. Beim Chat als Projekt-Pill aktiviert, nutzt die KI dieses Verzeichnis als cwd für Claude Code, Codex, Gemini CLI und für die project_*-Tools (jeder Provider).
Funktionen pro Projekt:
- Bilder (png/jpg/gif/webp/svg/avif/bmp): <img> inline - Videos (mp4/webm/mov/mkv/avi): <video controls> - Audio (mp3/wav/ogg/flac/m4a/aac): <audio controls> - PDF: <iframe> (75vh hoch) - Text/Code (50+ Endungen — py/js/ts/json/md/csv/sql/yaml etc.): <pre> - Office/Archive/Binär: Info-Box mit Download-Button
node_modules, .git, .venv, dist, build, __pycache__ u.a.) - Standard: Hidden-Files ausgeschlossen - ?include_hidden=true für Backups inkl. .env
nur lesen: - Claude Code CLI: --permission-mode=default + disallowed-tools - Codex CLI: --sandbox=read-only - Gemini CLI: --approval-mode=plan + allowed-tools-Whitelist - project_*-Tools: write/delete/shell → klare Fehlermeldung
Outputs-Unterordner: <projekt>/outputs/<datum>/ enthält alle vom Chat im Skill-Mode generierten Bilder/Videos/Files. Wird automatisch beim Erstellen befüllt, kann per Button im Chat-Header auch nachträglich für bestehende Outputs befüllt werden.
-----
Für SSH-Zugriff auf den NAS direkt aus dem Browser. Login mit den SSH-Credentials des NAS-Users.
Konfiguration: Admin → Web-Shell → SSH-Host, Port und Default-User setzen. NAS-spezifischer SSH-Port (z.B. 50199 statt 22) wird unterstützt.
-----
Während Claude Code, Codex oder Gemini CLI aktiv arbeiten, sieht der User live was der CLI tut:
● 📖 Lese src/auth.ts
✏️ Bearbeite schema.prisma
🔧 Führe `npm install` aus
✅ Befehl fertig
Funktioniert in allen Skill- und Klassik-Modes. Die Box erscheint automatisch wenn der Job läuft, verschwindet nach Done. Aktuelle Aktion wird mit pulsierendem Punkt hervorgehoben.
-----
Wenn ein Provider eine Datei im Container erzeugt und in der Antwort einen Pfad nennt, erscheint automatisch ein Download-Button unter der Assistant-Bubble.
Erkennung via:
{{download:/tmp/foo.html}} oder[[download:/tmp/foo.html]]
eine erlaubte Datei verweisen
Erlaubte Quell-Verzeichnisse: /tmp/, /var/tmp/, /data/.claude_home/, /data/outputs/, /home/, /data/media/
System-Verzeichnisse (/etc/, /usr/, /proc/, /root/, /var/log/) werden ignoriert.
Limits: 50 MB pro File, max 10 Files pro Antwort, ~50 Datei- Endungen auf Whitelist.
-----
Seit Mai 2026 unterstützt KnowSora Speech-to-Text (STT) und Text-to-Speech (TTS) mit drei wählbaren Engines.
|Engine |STT |TTS |Kosten |Latenz|Voraussetzung | |---------------------|----------------|----------------------------|-------------------------------------------|------|---------------------------| |Browser (Default)|Web Speech API |Web Speech API |gratis |<500ms|Chrome/Safari/Edge | |OpenAI |Whisper-1 |TTS-1 (MP3-Streaming) |~0.006 USD/Min STT, ~0.015 USD/1k chars TTS|1-2s |OpenAI-Provider mit API-Key| |Gemini |gemini-2.5-flash|gemini-3.1-flash-tts-preview|Free-Tier |3-8s |Gemini-Provider mit API-Key|
Browser-Engine ist die Default-Wahl und funktioniert am besten auf iPhone/iPad mit Apple-Stimmen. Unter Linux/Firefox eingeschränkt — dort auf OpenAI oder Gemini umstellen.
Voice ist immer eingebaut — keine Backend-Konfiguration nötig. In der Chat-Eingabezeile erscheint ein Mikrofon-Symbol. Voice-Engine + Stimme
einstellen (Zahnrad/⋮-Menü).
Wichtig: Browser erlauben Mikrofon-Zugriff nur über HTTPS oder localhost. Bei Selfhost-Setups mit Reverse-Proxy unbedingt Let’s Encrypt einrichten (siehe Sektion “Reverse-Proxy”), sonst geht Spracheingabe nicht.
KnowSora hat eingebautes Wörterbuch das ~50 Tech-Abkürzungen automatisch korrekt ausspricht:
automatisch und spielt sie nacheinander ab)
erlaubt — der erste Lautsprecher-Tap pro Tab muss manuell sein
-----
Seit Mai 2026 nutzt search_knowledge_base Hybrid-Retrieval statt reiner Vektor-Suche. Keine Konfiguration nötig — ist immer aktiv.
Jede Suche läuft parallel über zwei Engines:
Inhalte, auch bei Synonymen und Umschreibungen
Eigennamen, IDs, Codes
Die beiden Ranglisten werden über Reciprocal Rank Fusion (RRF) zu einer Top-Liste fusioniert. Tokenisierung: lowercase, deutsche + englische Stoppwörter raus, Mindestlänge 2 Zeichen.
BM25-Index wird pro KB-Filter im Speicher gehalten und automatisch invalidiert bei:
Erster Search-Call nach Cache-Invalidierung baut den Index neu auf (<100ms bei 10k Chunks).
Zusätzlich wird der Dateiname als Header in den Embed-Text eingebaut: [Quelle: filename.pdf]\n\n<chunk>. Dadurch werden Begriffe die nur im Dateinamen vorkommen mit-embedded und finden auch über Vektor-Suche die richtige Datei.
Der gespeicherte Chunk-Text bleibt original — User sehen den Prefix nicht in den Recherche-Ergebnissen.
Wichtig: Dokumente die VOR Mai 2026 hochgeladen wurden, haben den Filename-Prefix nicht. Über KB-Edit → “🔄 N bestehende Dokumente neu indizieren” lassen sich alle Docs einer KB mit aktuellen Einstellungen neu verarbeiten.
-----
Optional pro KB aktivierbar. Basiert auf der Anthropic-Methode anthropic.com/news/contextual-retrieval.
Beim Indexieren wird pro Chunk per LLM ein 1-2-Satz-Kontext aus dem Gesamtdokument generiert und VOR den Chunk gehängt — aber nur fürs Embedding. Der gespeicherte Chunk bleibt original.
Beispiel:
Chunk: “Die Antwort betrug 5,2 Mio. EUR im Q3.”
Embed-Input (mit Contextual): “Dieser Chunk stammt aus dem Q3-2024- Bericht der ACME GmbH und beschreibt den Quartalsumsatz. Die Antwort betrug 5,2 Mio. EUR im Q3.”
Resultat: Treffer-Relevanz um 30-50% besser für Fragen wie “Wie hoch war der ACME-Umsatz Q3?”.
KB öffnen → Bearbeiten → “🧠 Contextual Retrieval (smart chunking)” einschalten → LLM-Provider wählen → Speichern.
Provider-Auswahl pro KB:
Über Button “🔄 N bestehende Dokumente neu indizieren” im KB-Edit- Modal. Alle Docs werden auf pending gesetzt und vom Worker neu verarbeitet — diesmal mit Contextual Retrieval.
5s → 15s → 30s → 60s (max 5 Versuche pro Chunk)
DOC_PROCESS_TIMEOUT_MAX in .env
|Dok-Größe |Zeit mit Contextual (OpenRouter Free)| |----------|-------------------------------------| |5 Chunks |~30-40s | |20 Chunks |~2-3 min | |100 Chunks|~10-15 min | |500 Chunks|~45-60 min |
Mit OpenAI gpt-4o-mini etwa 5-10x schneller.
-----
KnowSora ist responsive ausgelegt und nutzt unter 768px Viewport-Breite ein angepasstes Layout:
Header zusammenklappbar. Auf Mobile sind die Selektoren-Zeile (Provider/Skill/Projekt/KB) und die Anhang-Bar per Default eingeklappt — nur Titel und Action-Buttons sind sichtbar. Maximaler Platz für den Chat. Der Chevron-Button rechts neben “Leeren” schaltet die Optionen ein und aus.
Selektoren mobile-safe. Provider/Skill/Projekt/KB-Dropdowns nutzen min(280-360px, calc(100vw - 24px)) als Breite mit maxHeight: 70vh und Scroll — kein Überlaufen am Bildschirmrand.
Admin User-Liste als Karten. Statt der Desktop-Tabelle erscheint auf Mobile pro User eine kompakte Karte mit Avatar, Username, Email, Rolle/Status-Badges und Edit/Delete-Buttons in einer Reihe.
Provider-Karten gestapelt. Lange Provider-Namen (z.B. “OpenAI (GPT-4o, etc.)”) werden nicht abgeschnitten — auf Mobile stehen Titel und Konfig-Buttons untereinander statt nebeneinander.
KI-Modelle-Menü nur für Admins sichtbar. Endkunden-User sehen den Eintrag nicht. Sie wählen Provider direkt im Chat-Dropdown — die Liste zeigt nur Provider mit usable=true (API-Key vorhanden oder OAuth aktiv). API-Keys werden nie ans Frontend zurückgegeben.
Voice auf Mobile. Mikrofon-Symbol bleibt prominent in der Hauptzeile. Weitere Voice-Optionen (Auto-Vorlesen, Sprach-Einstellungen, Projekt- Anhang) liegen im Overflow-Menü (⋮) damit das Eingabefeld groß bleibt. Voice-Settings als Bottom-Sheet mit großen Touch-Targets statt Popover.
-----
Wenn KnowSora hinter NPM oder einem anderen Proxy läuft, müssen folgende Timeouts erhöht werden, sonst werden lange KI-Anfragen gekillt:
NPM → Proxy Host → Advanced → Custom Nginx Configuration:
# Timeouts für lange KI-/CLI-Anfragen (bis 1 Stunde)
proxy_read_timeout 3600s;
proxy_send_timeout 3600s;
proxy_connect_timeout 60s;
# Uploads bis 200 MB
client_max_body_size 200M;
# WebSocket für CLI-Login Terminal
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
# Standard-Header
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Streaming nicht puffern
proxy_buffering off;
proxy_cache off;
Frontend-Polling-Logik macht automatisch exponential-backoff (800ms → 1.6s → 3.2s → 6.4s → max 8s) bei wiederholten Netzwerkfehlern, damit die Browser-Console nicht spamt während Let’s-Encrypt-Cert-Renewals.
-----
Render-Fehler im Frontend werden abgefangen — statt blank-screen siehst du eine Fallback-UI mit:
<details>Globale window.error + unhandledrejection Listener loggen zusätzlich in localStorage["knowsora-errors"] (letzte 30 Events) für Post-Mortem-Diagnose.
Bei OpenAI 400-Fehler:
temperatureumgestelltem Feld
Bei Gemini 400:
Klare Übersetzung von 404/503-Fehlern in deutsche User-Meldungen mit Hinweis welches Modell stattdessen funktioniert.
Chat-Anfragen laufen als Background-Job:
/api/chat/job/{id} → liest Status +Activity-Events live
localStorage["kh-job-<chat_id>"] gecached → Tabschließen + wieder aufmachen verbindet sich nahtlos wieder
Behoben in dieser Version: User-Nachrichten werden optimistisch mit id: Date.now() angezeigt. Echte Backend-ID wird via .then() in den State zurückgepatched. Bei sehr schnellem Edit unmittelbar nach Senden gibt es einen 404-Fallback der die Message neu speichert + lokal weitermacht.
Bei JWT-Expiration (HTTP 401) wird nicht hart per window.location.href navigiert — stattdessen Custom-Event knowsora-auth-expired → React-Router macht den Redirect zu /login ohne Page-Reload (kein temporärer Blank-Screen).
-----
|Endpoint |Methode |Zweck | |-----------------------------------------|-------------------------|----------------------------------------------------| |/api/auth/login |POST |Login (form-encoded), liefert JWT | |/api/auth/me |GET |Aktueller User | |/api/chats/ |GET/POST |Chat-Liste / neuen Chat anlegen | |/api/chats/{id} |PUT/DELETE |Chat ändern / löschen | |/api/chats/{id}/messages |GET |Messages eines Chats laden | |/api/chats/{id}/messages/{msg_id} |PUT |User-Message editieren + nachfolgende löschen | |/api/chats/{id}/copy-outputs-to-project|POST |Bestehende Chat-Outputs ins Projekt kopieren | |/api/chat/start |POST |KI-Anfrage als Background-Job starten | |/api/chat/job/{job_id} |GET |Job-Status + Activity-Events pollen | |/api/chat/job/{job_id}/cancel |POST |Laufenden Job abbrechen | |/api/skills/ |GET / POST / PUT / DELETE|Skill-Verwaltung | |/api/skills/tools |GET |Tool-Katalog | |/api/knowledge-bases/ |GET/POST/PUT/DELETE |KB-Verwaltung | |/api/documents/ |GET/POST |Dokument-Liste / Upload | |/api/projects/ |GET/POST |Projekt-Liste / anlegen | |/api/projects/{id}/browse |GET |Verzeichnis-Inhalt | |/api/projects/{id}/file |GET/DELETE |File lesen / löschen, ?download=1 für FileResponse| |/api/projects/{id}/upload |POST |Einzelne Datei hochladen | |/api/projects/{id}/upload-zip |POST |ZIP-Archiv hochladen + entpacken | |/api/projects/{id}/download-zip |GET |Ganzes Projekt als ZIP runterladen | |/api/projects/{id}/mkdir |POST |Verzeichnis anlegen | |/api/message-attachments/upload |POST |Bild/File für nächste Nachricht hochladen | |/api/message-attachments/{id} |DELETE |Anhang löschen | |/api/chat-outputs/{id}/download |GET |Provider-erzeugtes File runterladen | |/api/media/{user_id}/{path} |GET |KI-generiertes Medium (auth + owner-check) | |/api/ai-providers/ |GET/POST/PUT/DELETE |Provider-Verwaltung | |/api/ai-providers/{id}/test |POST |Test-Call an Provider | |/api/cli-login/start/{cli} |POST |OAuth-Login-Session starten | |/api/cli-login/ws/{cli} |WS |Terminal-Stream für CLI-Login | |/api/cli-login/status/{cli} |GET |Aktueller OAuth-Status | |/api/embed-models/catalog |GET |Verfügbare Embedding-Modelle | |/api/embed-models/activate |POST |Embedding-Modell wechseln | |/api/admin/users |GET/POST/PUT/DELETE |User-Verwaltung |
JWT-Token als Authorization: Bearer <token> Header.
-----
┌──────────────┐
│ Nginx Proxy │
│ Manager │
│ (optional) │
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌──────▼───────┐ ┌──────▼───────┐ ┌──────▼───────┐
│ Frontend │ │ Backend │ │ llama-chat │
│ Vite+React │ │ FastAPI │ │ llama.cpp │
│ Port 47822 │ │ Port 48823 │ │ Port 48824 │
└──────────────┘ └──────┬───────┘ └──────────────┘
│
┌─────────┼─────────┐
│ │ │
┌──────▼──┐ ┌────▼────┐ ┌──▼───────┐
│fastembed│ │ChromaDB │ │ DuckDB │
│ (ONNX, │ │persist │ │:memory: │
│in-proc) │ │ │ │query_tbl │
└─────────┘ └─────────┘ └──────────┘
│
┌───────┴────────┐
│ SQLite │
│ /data/ │
│ knowsora.db │
└────────────────┘
Alle Container im Host-Network-Modus — kein Port-Mapping, direkter LAN-Zugriff.
Daten-Persistenz — alles unter /data/ (oder dem Pfad aus DATA_DIR):
knowsora.db — Haupt-DBchroma/ — Vektor-Storemodels/ — GGUF-Dateienuploads/ — Chat-Attachments + Provider-Output-Filesmedia/<user>/<datum>/ — KI-Bilder/Videos (persistent unabhängig vom Chat)projects/<user>/<slug>/ — Coding-Projekteprojects/<user>/<slug>/outputs/<datum>/ — automatische Backup-Kopien aller Chat-Outputs für diesen Chat.claude_home/, .codex/, .gemini/ — CLI-OAuth-TokensBackup-Empfehlung: Den ganzen /data-Pfad sichern PLUS die .env (enthält SECRET_KEY) PLUS /data/.secret_key (Persistenz-Kopie des Keys). Bei Wiederherstellung muss der SECRET_KEY identisch zur ursprünglichen Installation sein, sonst sind verschlüsselte API-Keys und Sessions unbrauchbar.
-----
Backend startet nicht, Logs zeigen “permission denied” auf /data: HOST_UID/HOST_GID in .env passen nicht zum Volume-Owner. Fix:
chown -R 1000:1000 /volume3/docker/knowsora/data
Gemini CLI: “uv_os_get_passwd returned ENOENT”: Container-UID hat keinen passwd-Eintrag. Sollte automatisch beim Backend-Start gefixt werden. Falls nicht: docker compose down && docker compose up -d --build (kein --no-cache nötig — Dockerfile hat chmod 666 /etc/passwd /etc/group).
Gemini CLI: “folder is not trusted”: Automatisches Eintragen in trustedFolders.json schlägt fehl. Logs prüfen. Workaround: Backend-Container neu starten — beim nächsten Tool-Call wird der Eintrag neu geschrieben.
OpenAI: “max_tokens is not supported, use max_completion_tokens”: Sollte automatisch retried werden. Falls weiterhin: KI-Modelle → OpenAI → schauen welches Modell konfiguriert ist. Für gpt-5, o1, o3, o4 ist max_completion_tokens zwingend.
Veo Video: “Modell nicht gefunden / 503”:
veo-3.0-generate-001 (Premium) oderveo-3.0-fast-generate-001 (günstiger) oder veo-2.0-generate-001 (Fallback)
model: "veo-2.0-generate-001" als OverrideBilder/Videos verschwinden nach Tab-Wechsel: Sollte mit aktueller Version nicht mehr passieren — Media-Outputs werden als ChatOutput-DB-Rows persistiert. Falls doch: alte Bilder (vor Update) sind nicht migriert; neue Generierungen bleiben.
Projekt-Tools “Kein Projekt zugewiesen”: Bei den project_*-Tools muss in der Projekt-Pille oben im Chat explizit ein Projekt gewählt sein. Wechsel zu einem Chat ohne Projekt deaktiviert die Tools (sie geben klare Fehlermeldungen zurück).
Project_run_shell schlägt fehl mit “Schreibrechte deaktiviert”: Im Projekt-Editor “Schreibrechte” einschalten. Gleicher Toggle wie für die CLI-Provider (Claude Code, Codex, Gemini CLI).
Codex CLI: “bwrap: No permissions to create a new namespace”: Host-Kernel hat kernel.unprivileged_userns_clone=0. Typisch für UGREEN, Synology, manche Embedded-Linuxes. manage.sh update setzt das automatisch über CODEX_SANDBOX_MODE=danger-full-access in der .env. Falls die Detection nicht greift, manuell:
echo "CODEX_SANDBOX_MODE=danger-full-access" >> .env
docker compose up -d --force-recreate backend
docker exec knowsora_backend env | grep CODEX_SANDBOX_MODE
Codex CLI: “Reading additional input from stdin…” (exit 1): Behoben in aktueller Version — Codex’ Argument-Parser kann durch führende -/-- im Prompt verwirrt werden und fällt in den interaktiven stdin-Modus. Fix: -- als Separator vor dem Prompt (codex exec ... -- "<prompt>").
Update gemacht aber Frontend zeigt alte Version:
docker exec knowsora_frontend sh -c 'ls /usr/share/nginx/html/assets/index-*.js'
Hash sollte sich nach Update ändern.
unzip -o knowsora_release.zip && ./manage.sh update
neu öffnen oder iOS → Safari → Erweitert → Website-Daten löschen
Backend-Logs:
./manage.sh logs # alle Container, live
docker logs -f knowsora_backend
docker logs -f knowsora_frontend
Filter im Backend-Log: [worker], Job <id>, Skill '<name>', OpenAI, Gemini, Claude, Grok, project_.
-----
KnowSora wird von localeye.shop entwickelt und verkauft. Lizenzfragen, Support, Custom-Anpassungen: <https://localeye.shop> oder Mail an den Anbieter.
As of May 2026 · Web: localeye.shop
-----
-----
<a id="what-is-knowsora"></a>
KnowSora is a self-hosted AI assistant for individuals, teams, and small businesses that can replace paid tools like ChatGPT Team, Claude Projects, or Perplexity Pro — with the key difference that all your data stays on your own server.
Instead of locking you into a single vendor, KnowSora combines nine AI providers in parallel through a single interface. You choose per chat whether you want OpenAI, Claude, Gemini, Grok, OpenRouter (300+ models with free tier), or a local open-source model with no internet access — or the official command-line tools from Anthropic, OpenAI, and Google that are included in subscriptions (ChatGPT Plus, Claude Pro, Google Free Tier) at no additional API cost.
Who is this for?
to pay a separate monthly subscription for each
and code projects stored in a US vendor’s cloud
storage and compute to good use
document search, and project code access in a single tool
KnowSora has no SaaS backend, no external telemetry, no cloud dependency — except for the AI providers you explicitly enable. All knowledge bases, chats, project files, generated images and videos remain exclusively on your server.
-----
<a id="features"></a>
|#|Provider |Strengths |Requirements | |-|-------------------------|---------------------------------------------------|---------------------------------------| |1|Local LLM (llama.cpp)|100% offline, no API costs, any GGUF model |8+ GB RAM, optional iGPU | |2|OpenAI |GPT-4o / GPT-5 / o-Series, best tool calls |API key (pay-per-use) | |3|Anthropic Claude |Claude Sonnet 4.6 / Opus 4.7, best writing quality |API key | |4|Google Gemini |Gemini 2.5 Pro, Imagen 4, Veo 3 (video) |API key | |5|xAI Grok |Grok 4.3, Grok Imagine (image + video) |API key | |6|OpenRouter |300+ models, dedicated free tier with smart routing|API key (free tier without credit card)| |7|Claude Code CLI |Senior-engineer persona, file access |Anthropic Pro subscription | |8|Codex CLI |OpenAI’s official coding agent |ChatGPT Plus | |9|Gemini CLI |Google’s CLI, 1000 requests/day free |Google account (free) |
All providers are available simultaneously — you pick per chat which one to use, without re-authenticating.
finds proper names, exact identifiers, and semantic matches all at once
generates per-chunk context for 30-50% better retrieval accuracy
embedded so searches for terms only in filenames still work
against uploaded CSV/XLSX files (“How many orders last month?”)
(Whisper + TTS-1 with MP3 streaming), Google Gemini (free tier)
JSON, NAS, RAID, IP addresses, MACs, URLs)
Skills combine system prompt + toolbox into specialized modes. Built-in defaults:
(strict no-hallucination prompt as of May 2026)
Skills are fully editable — customize system prompt, tool list, or create your own.
Banana preserve face/hair 1:1, only change what you describe
for reels
video without actually doing so, KnowSora forces a real retry
code, Markdown — all directly in the UI
your files
active project folder
project_list_dir, project_read_file,project_write_file, project_delete, project_run_shell) available for every provider — including OpenAI/Claude/Gemini API, not just CLIs
/data/.secret_keythe AI providers you explicitly enable
-----
<a id="architecture"></a>
Three Docker containers, one shared volume:
┌────────────────────────────────────────────────────────┐
│ Frontend (nginx + React) │
│ Port: 47822 │
└──────────────────┬─────────────────────────────────────┘
│
┌──────────────────▼─────────────────────────────────────┐
│ Backend (FastAPI + Python 3.11) │
│ Port: 48823 │
│ ├─ SQLAlchemy + SQLite (users, chats, KBs, skills) │
│ ├─ ChromaDB + fastembed (vector search) │
│ ├─ Provider router (9 AI providers) │
│ ├─ Skill loop (tool-calling orchestrator) │
│ ├─ CLI wrapper (Claude Code, Codex, Gemini CLI) │
│ └─ Web terminal (xterm.js backend) │
└──────────────────┬─────────────────────────────────────┘
│ (optional)
┌──────────────────▼─────────────────────────────────────┐
│ Local LLM (llama.cpp + GGUF model) │
│ Port: 48800 (internal) │
└────────────────────────────────────────────────────────┘
Persistence: A single data directory (/data in container, mapped to /volume*/docker/knowsora/data on host) holds all databases, uploaded documents, AI-generated media, project files, and backups.
-----
<a id="requirements"></a>
|Component |Minimum |Recommended | |------------------|------------------------------|-----------------------| |CPU |x86_64 or ARM64, 2 cores |4+ cores | |RAM |4 GB (without local LLM) |16 GB (with Qwen3-7B) | |Disk |20 GB free |50+ GB (models + media)| |OS |Linux with kernel 5.x+ |Current Ubuntu / Debian| |Docker |24.0+ |latest | |Docker Compose|v2.0+ |latest | |Network |Outbound HTTPS to AI providers|— |
Optional for local LLM with hardware acceleration:
N-series) → pass /dev/dri into container
Cloud providers are optional. KnowSora runs fully offline with only the local LLM, if that’s what you want.
-----
<a id="installation"></a>
./manage.sh start — auto-creates .env, generates SECRET_KEY, builds and starts containershttp://<server-ip>:47822admin / admin, immediately set your own password-----
<a id="linux-server"></a>
1. Install Docker (Debian/Ubuntu):
curl -fsSL https://get.docker.com | sudo sh
sudo usermod -aG docker $USER
newgrp docker
Fedora:
sudo dnf install docker docker-compose-plugin
sudo systemctl enable --now docker
sudo usermod -aG docker $USER
2. Install KnowSora:
sudo mkdir -p /opt/knowsora
sudo chown $USER:$USER /opt/knowsora
cd /opt/knowsora
# Place knowsora_release.zip here (e.g., via scp)
unzip knowsora_release.zip
# Generate secrets
./manage.sh start # auto-generates .env + SECRET_KEY, then docker compose up
3. Optional: behind reverse proxy (nginx, Caddy, Traefik):
# /etc/nginx/sites-available/knowsora
server {
server_name knowsora.example.com;
listen 443 ssl http2;
# ssl_certificate ... ;
location / {
proxy_pass http://127.0.0.1:47822;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 3600s; # for long AI responses
proxy_send_timeout 3600s;
}
}
-----
<a id="ugreen-nas"></a>
Tested on UGREEN DXP4800 Plus with UGOS Pro. Also works on DXP4800, DXP6800 Pro, DXP8800 Plus.
1. Enable Docker:
UGOS → App Center → install Docker (available as an app).
2. Enable SSH:
UGOS → Control Panel → Terminal Service → enable SSH
3. SSH in and install:
ssh youruser@<nas-ip>
# Target folder on large volume (RAID volume)
sudo mkdir -p /volume3/docker/knowsora
sudo chown $USER:$USER /volume3/docker/knowsora
cd /volume3/docker/knowsora
# Upload ZIP (via UGOS web file manager or scp), then extract
unzip knowsora_release.zip # or ./manage.sh update (auto-extracts)
# Start — manage.sh creates .env, generates SECRET_KEY, brings containers up
./manage.sh start
No manual secret generation needed — ./manage.sh start automatically creates .env from .env.example and generates a SECRET_KEY using openssl/python3//dev/urandom. The key is persisted to /data/.secret_key so it survives .env loss.
4. UGREEN-specific note — Codex CLI sandbox:
UGOS kernel has kernel.unprivileged_userns_clone=0 set, which blocks bubblewrap (Codex CLI’s sandbox). manage.sh start detects this automatically and sets CODEX_SANDBOX_MODE=danger-full-access in .env. The container is already isolated by Docker anyway, so no real security loss.
5. Port forwarding (if exposing externally):
UGOS → Control Panel → Network → Router Configuration → forward port 47822 to NAS IP. Recommended: use a reverse proxy instead (e.g., nginx-proxy-manager) to terminate HTTPS.
-----
<a id="synology-dsm"></a>
Tested on DS920+, DS923+, DS1522+ under DSM 7.2.
1. Install Container Manager:
DSM → Package Center → search “Container Manager” → install.
2. Enable SSH:
DSM → Control Panel → Terminal & SNMP → enable SSH service
3. Install via SSH:
ssh youruser@<nas-ip>
# Typical Synology path
sudo mkdir -p /volume1/docker/knowsora
sudo chown $USER:users /volume1/docker/knowsora
cd /volume1/docker/knowsora
unzip knowsora_release.zip
./manage.sh start # handles .env + SECRET_KEY automatically
4. Synology-specific note — bridge networking:
DSM defaults to macvlan for containers, which complicates inter-container communication. KnowSora ships its own bridge network in docker-compose.yml that works without issues.
5. Reverse proxy in DSM:
DSM → Control Panel → Login Portal → Advanced → Reverse Proxy → source knowsora.your-domain.com:443 → target localhost:47822. Manage HTTPS certificates via Let’s Encrypt directly in DSM.
-----
<a id="qnap"></a>
Tested on TS-464, TS-873A, TVS-h674 under QTS 5.1 / QuTS hero h5.1.
1. Install Container Station:
QTS → App Center → search “Container Station” → install.
2. Enable SSH:
QTS → Control Panel → Telnet/SSH → enable SSH
3. Install:
ssh admin@<nas-ip>
# Typical QNAP path
mkdir -p /share/Container/knowsora
cd /share/Container/knowsora
unzip knowsora_release.zip
./manage.sh start # auto-generates .env + SECRET_KEY, then docker compose up
4. QNAP-specific:
Container Station has its own GUI for compose stacks. You can also import the compose file there and manage it via the GUI.
-----
<a id="raspberry-pi"></a>
Tested on Raspberry Pi 5 (8 GB) with Raspberry Pi OS 64-bit (Debian Bookworm). Pi 4 (4 GB) also works, local LLM only very slow.
1. OS prerequisites:
# Verify 64-bit OS
uname -m # must show "aarch64"
sudo apt update && sudo apt upgrade -y
curl -fsSL https://get.docker.com | sudo sh
sudo usermod -aG docker $USER
newgrp docker
2. More swap (important with only 4 GB RAM):
sudo dphys-swapfile swapoff
sudo sed -i 's/CONF_SWAPSIZE=.*/CONF_SWAPSIZE=4096/' /etc/dphys-swapfile
sudo dphys-swapfile setup
sudo dphys-swapfile swapon
3. Install like Linux Server (see above). KnowSora container images are multi-arch (amd64 + arm64), automatically build the right image.
Important on Pi: Disable local LLM — otherwise every response takes 30+ seconds. Comment out the llama_chat service in docker-compose.yml or simply don’t start it:
docker compose up -d --build backend frontend # no llama_chat
Cloud providers (OpenAI, Gemini, Claude) work fine on Pi.
-----
<a id="windows"></a>
1. Prerequisites:
docker.com/products/docker-desktop)2. Recommended: in WSL2 rather than PowerShell (paths, permissions, performance):
# In PowerShell as Admin
wsl --install -d Ubuntu
After reboot, log into Ubuntu WSL, then:
# Inside WSL Ubuntu
mkdir -p ~/knowsora
cd ~/knowsora
# Drag & drop ZIP into WSL window, or
# cp /mnt/c/Users/<user>/Downloads/knowsora_release.zip .
unzip knowsora_release.zip
./manage.sh start # auto-generates .env + SECRET_KEY, then docker compose up
Open browser at http://localhost:47822.
3. Find data volume in Windows:
In WSL: ~/knowsora/data/ In Explorer: \\wsl$\Ubuntu\home\<user>\knowsora\data\
-----
<a id="macos"></a>
1. Prerequisites:
docker.com/products/docker-desktop)using local LLM)
2. Install:
# Open terminal
mkdir -p ~/knowsora && cd ~/knowsora
# Extract ZIP
unzip ~/Downloads/knowsora_release.zip
./manage.sh start # auto-generates .env + SECRET_KEY, then docker compose up
Browser → http://localhost:47822.
Apple Silicon (M1/M2/M3): all container images are multi-arch, run natively as ARM64. Better performance than on Intel Mac.
-----
<a id="first-steps"></a>
1. Open browser at http://<server-ip>:47822
2. Login: admin / admin
3. Set your own password immediately:
4. Optional: activate cloud providers:
5. Create your first knowledge base:
6. Start your first chat:
-----
<a id="updates"></a>
KnowSora updates come as knowsora_release.zip. The workflow is the same on all systems:
cd /path/to/knowsora
# Place new ZIP in project directory (via scp, SFTP, web upload)
# Run update
./manage.sh update
What manage.sh update does automatically:
unzip is missing — last resort: Docker-based)
.env.example are addedto your .env, existing values are preserved
namespaces
No data is lost — everything under /data/ stays untouched.
For major updates: make a backup first (see below).
-----
<a id="configuration"></a>
All configuration lives in .env. You don’t need to touch this for a default install — ./manage.sh start creates the file and generates a SECRET_KEY automatically. Edit only when changing defaults (ports, data path, timeouts, preconfiguring provider keys).
|Variable |Purpose | |------------|-----------------------------------------------------------------------------------------------------------------------------------------| |SECRET_KEY|Session signing (JWT) and key derivation for API-key encryption. Auto-generated by manage.sh if empty; persisted to /data/.secret_key|
⚠️ Never changeSECRET_KEYonce data exists in the DB. Otherwise all stored API keys become unusable and all sessions must re-login. The Fernet encryption key for DB-stored API keys is derived fromSECRET_KEYvia PBKDF2 — there is no separateFERNET_KEYvariable.
|Variable |Default |Purpose | |-----------------------|----------------------|---------------------------------------------------------------------| |HOST_UID / HOST_GID|1000:1000 |UID containers run under, for file permissions | |DATA_DIR |/data |In-container path | |LLM_HTTP_TIMEOUT |3600 |Seconds for long AI responses | |CHAT_MODEL_PATH |(empty) |GGUF file for local LLM, e.g. /models/qwen3-4b-q4_k_m.gguf | |CODEX_SANDBOX_MODE |(empty) |NAS workaround: danger-full-access if kernel namespaces are blocked| |VEO_MODEL |veo-3.0-generate-001|Video model, fallback to veo-2.0 if Veo 3 not enabled | |VEO_MAX_POLL_S |600 |Max wait time for video rendering (seconds) | |PROJECT_SHELL_TIMEOUT|90 |Hardcap for project_run_shell (seconds) |
Full list with explanations: read .env.example.
-----
<a id="provider-setup"></a>
Each provider has its own card in the UI with setup instructions. Quick overview:
Place GGUF model in data/models/, set in .env:
CHAT_MODEL_PATH=/models/qwen3-4b-q4_k_m.gguf
Restart container. Recommendations:
platform.openai.com/api-keys → create API key → enter in KnowSora under AI Models → OpenAI. Models: gpt-4o, gpt-5, o1-mini.
KnowSora auto-detects whether a model requires max_completion_tokens instead of max_tokens.
console.anthropic.com → API Keys → enter in KnowSora. Models: claude-sonnet-4-6, claude-opus-4-7.
aistudio.google.com/apikey → generate API key. Important: Gemini API must be enabled in Google Cloud Console: console.developers.google.com/apis/api/generativelanguage.googleapis.com
Models: gemini-2.5-pro, gemini-2.5-flash.
console.x.ai → API key + load credits. Models: grok-4.3 (recommended), grok-4.20, grok-imagine-image-quality, grok-imagine-video.
Important: Grok has no OAuth flow — not even with X Premium / SuperGrok subscription. API key only. Credits must be explicitly loaded, there is no free tier.
AI Models → OpenRouter → API key (generate at openrouter.ai, Google/GitHub login possible, no credit card needed for free tier).
What makes OpenRouter special: one API key, access to 300+ models from OpenAI, Anthropic, Google, xAI, Meta, DeepSeek, Mistral and more — including dedicated free tier models for completely free use (with rate limit).
Recommended model choice:
openrouter/free (default, killer feature) — Smart Routing,picks the best free model at runtime based on the active skill: - Coding Assistant → Qwen3 Coder (1M context) - Knowledge Research → Llama 3.3 70B / DeepSeek V4 / Gemini 2.0 Flash - Data Analyst → DeepSeek V4 Flash (reasoning) - Web Research → Llama 3.3 / DeepSeek - Media Generator → first general free model with tool support - Coder models are automatically excluded for non-coding skills (anti_hints in the heuristic)
qwen/qwen3-coder:free — top coding model, 1M contextdeepseek/deepseek-v4-flash:free — reasoning, 1M contextmeta-llama/llama-3.3-70b-instruct:free — solid general purposegoogle/gemini-2.0-flash-exp:free — multimodal, fastopenai/gpt-5 — paid, if you’ve loaded creditsanthropic/claude-sonnet-4.6 — paidPer-skill override: you can pin a preferred free model per skill under Skills → Edit → “🌐 Preferred OpenRouter Free Model”. Smart Routing will use it instead of the heuristic. Leave empty for auto.
Rate limits (as of May 2026):
20 req/min
KnowSora features for OpenRouter:
active skill (capability scoring by tool support, context size, model family)
via /api/v1/models (1h cache)
purchased and consumed credits
KnowSora automatically tries up to 2 other free models (filters for tool-calling-capable if skill is active)
HTTP-Referer + X-Titleheaders so your usage shows on OpenRouter leaderboards
Cache refresh if new free models are expected:
curl -X POST http://localhost:48823/api/openrouter/refresh-cache \
-H "Authorization: Bearer $YOUR_KNOWSORA_TOKEN"
For other hosters with OpenAI API format (Together, Groq, local APIs, etc.). AI Models → Custom → base URL + API key + model ID.
OpenRouter should use the dedicated provider above — otherwise you lose free tier detection, auto-fallback, and credits display.
In KnowSora → AI Models → pick CLI → CLI Login.
Follow the login instructions in the modal terminal:
code back into terminal
KnowSora polls every 2 seconds for successful login and closes the window automatically. Subscription costs:
-----
Since May 2026, KnowSora supports Speech-to-Text (STT) and Text-to- Speech (TTS) with three switchable engines.
|Engine |STT |TTS |Cost |Latency|Requires | |---------------------|----------------|----------------------------|-------------------------------------|-------|--------------------------| |Browser (default)|Web Speech API |Web Speech API |free |<500ms |Chrome/Safari/Edge | |OpenAI |Whisper-1 |TTS-1 (MP3 streaming) |~$0.006/min STT, ~$0.015/1k chars TTS|1-2s |OpenAI provider configured| |Gemini |gemini-2.5-flash|gemini-3.1-flash-tts-preview|free tier |3-8s |Gemini provider configured|
Browser engine is the default and works excellent on iPhone/iPad (Apple voices). Limited on Linux/Firefox — switch to OpenAI or Gemini there.
Voice is built-in — no backend configuration needed. A microphone icon appears in the chat input bar. Engine / voice / language can be set per browser profile via the voice-settings popover (gear / ⋮ menu).
Important: Browsers only grant microphone access over HTTPS or localhost. For self-hosted setups behind a reverse proxy, set up Let’s Encrypt (see “Reverse proxy” section) — otherwise voice input won’t work.
~50 IT acronyms are automatically pronounced correctly:
automatically and plays them sequentially)
the first speaker tap per tab must be manual
-----
Since May 2026, search_knowledge_base uses hybrid retrieval instead of pure vector search. No configuration needed — always on.
Every search runs in parallel across two engines:
content, also catches synonyms and paraphrases
The two ranked lists are merged via Reciprocal Rank Fusion (RRF). Tokenization: lowercase, German + English stopwords removed, min length 2 characters.
BM25 index is kept in memory per KB filter set and automatically invalidated on:
First search after invalidation rebuilds the index (<100ms for 10k chunks).
Additionally, file name is prepended to embed text as: [Source: filename.pdf]\n\n<chunk>. Terms only appearing in file names get embedded too, so searches for them find the correct document.
The stored chunk text remains unchanged — users don’t see the prefix in research results.
Note: Documents uploaded BEFORE May 2026 don’t have the filename prefix yet. Via KB edit → “🔄 N existing documents reindex” button you can re-process all docs with current settings.
-----
Optional per KB. Based on Anthropic’s method anthropic.com/news/contextual-retrieval.
When indexing, an LLM generates a 1-2 sentence context per chunk from the full document and prepends it — but only for embedding. The stored chunk stays original.
Example:
Chunk: “The amount was 5.2M EUR in Q3.”
Embed input (with contextual): “This chunk is from ACME Inc’s Q3 2024 report and describes quarterly revenue. The amount was 5.2M EUR in Q3.”
Result: 30-50% better retrieval relevance for questions like “What was ACME’s Q3 revenue?”.
KB → Edit → enable “🧠 Contextual Retrieval (smart chunking)” → pick LLM provider → save.
Provider options per KB:
Via “🔄 N existing documents reindex” button in KB edit modal. All docs are set to pending and reprocessed by the worker — this time with contextual retrieval.
5s → 15s → 30s → 60s (max 5 attempts per chunk)
DOC_PROCESS_TIMEOUT_MAX in .env
|Doc size |Time with contextual (OpenRouter Free)| |----------|--------------------------------------| |5 chunks |~30-40s | |20 chunks |~2-3 min | |100 chunks|~10-15 min | |500 chunks|~45-60 min |
With OpenAI gpt-4o-mini, roughly 5-10x faster.
-----
<a id="troubleshooting"></a>
docker compose logs backend frontend
Most common causes:
47822 or 48823 already taken — change indocker-compose.yml
/data → chown $USER:$USER -R data/OAuth token file in backend container has expired. KnowSora → AI Models → CLI → CLI Login again.
docker stats)/dev/dri in docker-compose.yml→ llama.cpp uses VAAPI
NAS kernel has unprivileged_userns_clone=0. Set in .env:
CODEX_SANDBOX_MODE=danger-full-access
Restart backend. manage.sh start does this automatically if it detects the situation.
When xAI returns 404 (sometimes auth/region mismatch): just try again. KnowSora detects the bug and aborts after ~5 sec with clear error message (instead of polling for minutes).
If Veo says “PERMISSION_DENIED”: enable Gemini API in Google Cloud Console (link in error message).
KnowSora has built-in hallucination detection — if the LLM says “calling tool now” without actually calling it, a force-retry is triggered automatically. Should no longer happen. If it does: check backend log:
docker logs --since 10m knowsora_backend | grep -iE "halluzin|force-retry"
Clear browser cache (Ctrl+Shift+R / Cmd+Shift+R). Restart nginx container if needed: docker compose restart frontend.
docker logs --tail 200 knowsora_backend
docker logs --tail 200 knowsora_frontend
docker logs --tail 200 knowsora_llama_chat
Follow live:
docker compose logs -f backend
-----
<a id="backup"></a>
All relevant data lives in the data/ directory:
data/
├── knowsora.db # SQLite with users, chats, KBs, skills, settings
├── chroma/ # vector DB
├── uploads/ # uploaded documents, chat attachments
├── media/ # AI-generated images + videos
├── projects/ # project directories
├── models/ # GGUF models (local LLM)
├── fastembed_cache/ # embedding model cache
└── .secret_key # SECRET_KEY backup
cd /path/to/knowsora
docker compose stop # stop containers
tar czf knowsora-backup-$(date +%F).tar.gz data/ .env
docker compose start
IMPORTANT: also back up .env — otherwise SECRET_KEY and SECRET_KEY are gone and all API keys become unusable.
When the full data/ is too large:
docker compose stop backend
tar czf knowsora-db-$(date +%F).tar.gz data/knowsora.db data/chroma/ data/.secret_key .env
docker compose start backend
Back up media + uploads separately via rsync if needed.
cd /path/to/knowsora
docker compose down
tar xzf knowsora-backup-2026-05-16.tar.gz
docker compose up -d
-----
<a id="uninstall"></a>
cd /path/to/knowsora
docker compose down -v # -v also removes volumes
docker rmi knowsora-backend knowsora-frontend knowsora-llama-chat
cd ..
rm -rf knowsora/ # ⚠️ irreversibly deletes all data
Make a data/ backup first if there’s anything you want to keep!
-----
knowsora.md — developer docs, internal architecture, lessonslearned, manage.sh internals
knowledge.md — knowledge base concept and RAG workflow indetail
.env.example — full ENV variable list with defaultsKnowSora is private self-hosted software without commercial support. For questions or bugs: check backend logs, read .env.example, adjust code yourself if needed — source is openly readable inside the container:
docker exec -it knowsora_backend bash
cd /app
ls -la
Have fun with KnowSora.
Preise